互联网信息爆发式增长,如何有效的获取并利用这些信息是搜索引擎工作中的首要环节。数据抓取系统作为整个搜索系统中的上游,主要负责互联网信息的搜集、保存、更新环节,它像蜘蛛一样在网络间爬来爬去,因此通常会被叫做“spider”。例如我们常用的几家通用搜索引擎蜘蛛被叫做:Baiduspider、Googlebot、Sogou Web Spider等。
Spider抓取系统是搜索引擎数据来源的重要保证,如果把web理解为一个有向图,那么spider的工作过程可以认为是对这个有向图的遍历。从一些重要的种子 URL开始,通过页面上的超链接关系,不断的发现新URL并抓取,尽最大可能抓取到更多的有价值网页。对于类似百度这样的大型spider系统,因为每时 每刻都存在网页被修改、删除或出现新的超链接的可能,因此,还要对spider过去抓取过的页面保持更新,维护一个URL库和页面库。
1、spider抓取系统的基本框架
如下为spider抓取系统的基本框架图,其中包括链接存储系统、链接选取系统、dns解析服务系统、抓取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。
2、spider抓取过程中涉及的网络协议
搜索引擎与资源提供者之间存在相互依赖的关系,其中搜索引擎需要站长为其提供资源,否则搜索引擎就无法满足用户检索需求;而站长需要通过搜索引擎将自己的 内容推广出去获取更多的受众。spider抓取系统直接涉及互联网资源提供者的利益,为了使搜素引擎与站长能够达到双赢,在抓取过程中双方必须遵守一定的 规范,以便于双方的数据处理及对接。这种过程中遵守的规范也就是日常中我们所说的一些网络协议。以下简单列举:
http协议:超文本传输协议,是互联网上应用最为广泛的一种网络协议,客户端和服务器端请求和应答的标准。客户端一般情况是指终端用户,服务器端即指网 站。终端用户通过浏览器、蜘蛛等向服务器指定端口发送http请求。发送http请求会返回对应的httpheader信息,可以看到包括是否成功、服务 器类型、网页最近更新时间等内容。
https协议:实际是加密版http,一种更加安全的数据传输协议。
UA属性:UA即user-agent,是http协议中的一个属性,代表了终端的身份,向服务器端表明我是谁来干嘛,进而服务器端可以根据不同的身份来做出不同的反馈结果。
robots协议:robots.txt是搜索引擎访问一个网站时要访问的第一个文件,用以来确定哪些是被允许抓取的哪些是被禁止抓取的。 robots.txt必须放在网站根目录下,且文件名要小写。详细的robots.txt写法可参考 http://www.robotstxt.org 。百度严格按照robots协议执行,另外,同样支持网页内容中添加的名为robots的meta标 签,index、follow、nofollow等指令。
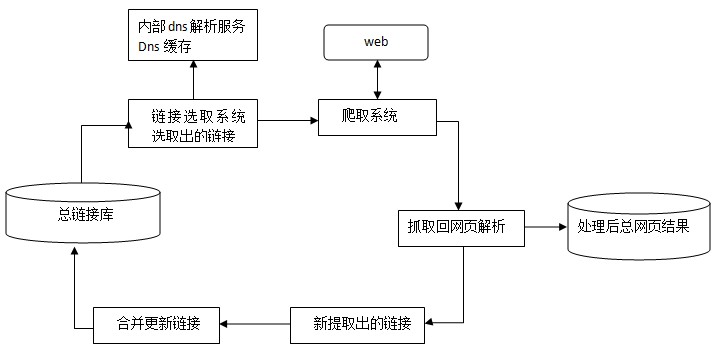
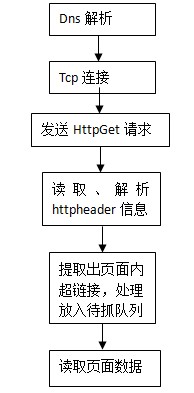
3、spider抓取的基本过程
spider的基本抓取过程可以理解为如下的流程图:
(百度资源搜索平台)